Building Confidence in AI Applications: A Methodology for Iterative Development

As AI applications move from prototypes to production systems, one question becomes increasingly critical: how can we be confident that each iteration actually improves our system? Every change brings new features, enhanced capabilities, or performance improvements - but also the risk of regressions or unintended consequences. For engineering teams, the ability to confidently evaluate model performance becomes as crucial as the development itself. Whether you're fine-tuning a language model, testing new prompts, or deploying a production AI service, you need a systematic way to validate improvements and detect potential issues before they reach users. This post introduces Neradot's evaluation methodology, a structured approach that brings clarity and reliability to the iterative AI development process - one that has been battle-tested in enterprise environments, as we'll see through Monday.com's implementation of their AI Blocks platform.
What Makes an Experiment?
At its core, an AI evaluation experiment consists of three essential components: a task to evaluate, a dataset to test with, and metrics to measure performance. Let's break this down using a practical example: evaluating an LLM's ability to solve basic math problems.
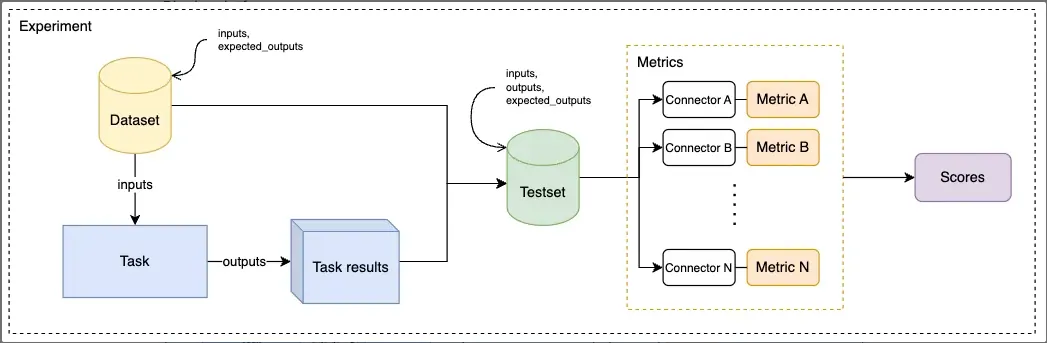
A Task is applied on a dataset. Then, using the Task results with the dataset a test set is created. Next, each metric is applied on the whole test set, connectors are used to align the data structure for each metric. The metric calculates the score based on the test set.
The Task
The task defines what we're evaluating - the specific AI capability or service under test. In our example, the task is an LLM-based mathematics solver. When given a natural language math question like "If I had 4 apples and ate 1, how many apples do I have left?", it should understand the context and return the correct numerical answer. This task definition gives our experiment clear boundaries and purpose.
The Dataset
A dataset provides the test cases for our experiment. Each item in the dataset must include inputs and may optionally include expected outputs. Here's how a simple mathematics dataset might look:
{
"inputs": {
"question": "If I had 4 apples and ate 1, how many apples do I have left?"
},
"expected_output": 3
},
{
"inputs": {
"question": "Tom has 7 marbles and gives 2 to Sarah. How many marbles does Tom have now?"
},
"expected_output": 5
},
{
"inputs": {
"question": "A recipe calls for 3 eggs per batch. If I want to make 2 batches, how many eggs do I need?"
},
"expected_output": 6
}
]
The Testset
When we run our task against the dataset, we generate a testset - a collection of triplets containing the original input, the model's output, and the expected output (when available):
[
{
"inputs": {
"question": "If I had 4 apples and ate 1, how many apples do I have left?"
},
"output": 3,
"expected_output": 3
},
{
"inputs": {
"question": "Tom has 7 marbles and gives 2 to Sarah. How many marbles does Tom have now?"
},
"output": 5,
"expected_output": 5
},
{
"inputs": {
"question": "A recipe calls for 3 eggs per batch. If I want to make 2 batches, how many eggs do I need?"
},
"output": 6.0,
"expected_output": 6
}
]
The metrics: From Testset to Scores
When a metric processes a testset, it produces a structured output that combines individual measurements with aggregated score and detailed logs. Here's an example using an exact equality metric that checks if the model's numerical answers exactly match the expected values:
{
"IsEquals": {
"name": "Equality rate",
"description": "Calculate the average of the amount of items that are exact equals between the predicted and the true values.",
"support": 3,
"scores": {
"average": 0.66
},
"measurements": [
true,
true,
false
],
"logs": [
{
"index": 2,
"label": "failure",
"reason": "6.0 != 6, types: <class 'float'> != <class 'int'>"
}
]
}
}
This output shows us several key components:
- Metric Definition: Name and description explain what's being measured
- Support: Number of items evaluated (3 in this case)
- Scores: Aggregated results (66% accuracy)
- Measurements: Individual true/false results for each test item
- Logs: Detailed information about failures, helping debug issues like type mismatches
Measuring Success: The Metrics Framework
The key to meaningful AI evaluation lies in selecting the right metrics - measurements that truly capture what success means for your application. Building on our testset results, these metrics transform raw model outputs into actionable insights. They generally fall into two critical categories:
- Performance Metrics These metrics focus on the operational aspects of your AI application:
- Latency: How quickly does the model respond?
- Token Usage: How efficiently does it use resources?
- Quality Metrics These evaluate the actual outputs of your model:
- Supervised metrics require expected outputs (like our math problems)
- Unsupervised metrics evaluate output properties without ground truth
- Can be objective (exact match) or subjective (using LLM judgment)
For our math solver example, combining both performance and quality metrics gives us a complete picture - we can track not just whether answers are correct, but also if they're being delivered efficiently enough for production use. This comprehensive approach to measurement ensures that each iteration genuinely improves what matters most for your specific use case.
Case Study: Monday.com's AI Blocks Evaluation Framework
Monday.com, working with Neradot's team, implemented our evaluation methodology across their AI Blocks platform - a suite of AI-powered workflow automation tools. Each block represents a distinct AI task requiring its own specialized evaluation approach. For example, their "Categorize" block demonstrates how our framework adapts to complex real-world requirements:
{
"task": "Classification",
"testset": [
{
"inputs": {
"text": "Schedule team meeting for next week",
"language": "en"
},
"output": "meeting_scheduling",
"expected_output": "meeting_scheduling"
},
{
"inputs": {
"text": "需要审核新的营销方案",
"language": "zh"
},
"output": "review_request"
"expected_output": "review_request"
}
],
"metrics": {
"Classificaiton": {
"scores": {
"precision": 0.92,
"recall": 0.89,
}
},
"LanguageConsistency": {
"scores": {
"cross_language_consistency": 0.87
}
}
"Performance": {
"scores": {
"p95_latency_ms": 245,
"token_usage": 513
}
}
}
}
Neradot's evaluation methodology provided solutions to key enterprise AI development challenges:
- Cross-Language Consistency: The framework's flexible metric system enabled Monday.com to implement specialized cross-language evaluation metrics, ensuring consistent performance across their global user base. These metrics were easily standardized across all AI blocks through the methodology's unified approach.
- Dataset Quality Assurance: Through structured testset generation and detailed error analysis, the framework helped identify and correct labeling inconsistencies in manually labeled datasets, improving the reliability of evaluations.
- Efficient Metric Management: The methodology's modular approach allowed Monday.com to establish a shared foundation of performance metrics while maintaining task-specific measurements. This enabled efficient reuse of evaluation components across similar blocks like "Categorize" and "Detect Sentiment" while preserving the flexibility to add specialized metrics when needed.
This systematic approach to evaluation has become integral to Monday.com's AI development process, enabling rapid iteration while maintaining reliability across their diverse AI feature suite.
Conclusion
The journey from prototype to production in AI development is paved with iterations, each promising improvements but also carrying risks of regressions or unintended consequences. A robust evaluation methodology, as demonstrated through our examination of core components and Monday.com's real-world implementation, provides the confidence needed to move quickly while maintaining quality.
By breaking down evaluation into clear components - tasks, datasets, testsets, and metrics - teams can create reproducible experiments that validate improvements and catch potential issues before they reach production. This structured approach not only accelerates development but also builds trust in AI systems through measurable, consistent results.
Whether you're developing a single AI feature or managing a suite of AI-powered tools, investing in a comprehensive evaluation framework pays dividends in development speed, reliability, and the ability to confidently push the boundaries of what's possible with AI.